多核平臺下串行程序運行時的自動并行化加速方法
《多核平臺下串行程序運行時的自動并行化加速方法》是
上海交通大學
于2010年8月27日申請的專利,該專利的公布號為CN101916185A,授權公布日為2010年12月15日,發(fā)明人是過敏意、楊藍麒、李陽、陳鵬宇、楊曉鵬、王穩(wěn)寅、沈耀。
一種計算機技術領域的多核平臺下串行程序運行時的自動并行化加速方法,新增可共享讀取的程序計數(shù)器寄存器組,并在操作系統(tǒng)中建立自動并行加速線程,選擇一個線程作為加速的對象,然后實時地分析此線程將要執(zhí)行到的指令代碼,并對其中執(zhí)行循環(huán)的指令代碼進行修改,達到使被加速線程自動并行執(zhí)行的目的。該發(fā)明在運行時對程序進行自動并行,不用對程序進行預先的處理,整個過程由操作系統(tǒng)完成,對于用戶完全透明。該發(fā)明能夠在有空閑的CPU核時自動利用空閑資源對程序進行并行加速,免去等待預先處理程序的時間,也省去用戶手動轉換程序的麻煩。
2020年7月14日,《多核平臺下串行程序運行時的自動并行化加速方法》獲得第二十一屆中國專利獎優(yōu)秀獎。
多核平臺下串行程序運行時的自動并行化加速方法基本信息
| 中文名 | 多核平臺下串行程序運行時的自動并行化加速方法 | 申請人 | 上海交通大學 |
|---|---|---|---|
| 申請日 | 2010年8月27日 | 申請?zhí)?/th> | 2010102640748 |
| 公布號 | CN101916185A | 公布日 | 2010年12月15日 |
| 發(fā)明人 | 過敏意、楊藍麒、李陽、陳鵬宇、楊曉鵬、王穩(wěn)寅、沈耀 | 地????址 | 上海市閔行區(qū)東川路800號 |
| Int. Cl. | G06F9/38(2006.01)I | 代理機構 | 上海交達專利事務所 |
| 代理人 | 王錫麟、王桂忠 | 類????別 | 發(fā)明專利 |
《多核平臺下串行程序運行時的自動并行化加速方法》涉及的是一種計算機技術領域的方法,具體是一種多核平臺下串行程序運行時的自動并行化加速方法。
多核平臺下串行程序運行時的自動并行化加速方法造價信息
1.一種多核平臺下串行程序運行時的自動并行化加速方法,其特征在于,包括以下步驟:
第一步,建立一個共享讀取的程序計數(shù)寄存器組SPC,該寄存器組中寄存器的個數(shù)與CPU核的數(shù)目相同,每個寄存器分別與對應的CPU核相連以實時地儲存該CPU核的程序計數(shù)器值;
第二步,當存在空閑的CPU核時,進行加速對象選擇處理,得到自動并行加速線程的加速對象為線程P;
第三步,當線程P存在已分析指令集合Sp時,載入該集合Sp;否則,為線程P新建一個集合Sp,對線程P所在的CPU核進行讀取處理,得到線程P所在的CPU核當前正在讀取的指令Ic,并由Ic追蹤線程P下一條將要執(zhí)行指令的地址,將追蹤分析的指令代碼和跳轉關系加入集合Sp中;
第四步,采用第三步的方法,得到線程P將要執(zhí)行的所有指令,當集合Sp中每次加入條件轉移指令后且集合Sp中存在循環(huán)代碼時,進行進度校驗和替換處理;
第五步,當線程P被調(diào)度出CPU核時,系統(tǒng)以中斷方式將該事件連同當時的SPCp值發(fā)送給自動并行加速線程,當自動并行加速線程正在替換處理中時,則使用此時的SPCp值作為讀取Ic的依據(jù),繼續(xù)執(zhí)行替換處理直到退出該步驟;否則,自動并行加速線程根據(jù)當時的SPCp值讀取Ic,清空或更新集合Sp,其結果等待線程P被調(diào)入時繼續(xù)使用;
第六步,返回第二步,開始處理新的需要加速的線程。
2.根據(jù)權利要求1所述的多核平臺下串行程序運行時的自動并行化加速方法,其特征是,第一步中所述的共享讀取是:每個CPU核實時讀取寄存器組中每個寄存器存儲的其它CPU核的程序計數(shù)器值。
3.根據(jù)權利要求1所述的多核平臺下串行程序運行時的自動并行化加速方法,其特征是,第二步中所述的加速對象選擇處理,是:當正在運行且未被加速的用戶線程中存在CPU占用率最高的線程時,則選擇該線程作為自動并行加速線程的加速對象;否則,時間t后,再次選擇正在運行且未被加速的用戶線程中CPU占用率最高的線程作為自動并行加速線程的加速對象,直至得到自動并行加速線程的加速對象。
4.根據(jù)權利要求3所述的多核平臺下串行程序運行時的自動并行化加速方法,其特征是,所述的時間t是系統(tǒng)的調(diào)度時間片大小。
5.根據(jù)權利要求1所述的多核平臺下串行程序運行時的自動并行化加速方法,其特征是,第三步中所述的讀取處理,是:讀取線程P所在的CPU核的程序計數(shù)寄存器的值,將得到的虛擬地址轉換為物理地址,然后從該物理地址得到線程P所在的CPU核正在執(zhí)行的指令Ic,當集合Sp中包括指令Ic時,刪除集合Sp中Ic以前的指令記錄,并根據(jù)集合Sp追蹤線程P下一條將要執(zhí)行的指令;否則,清空集合Sp。
6.根據(jù)權利要求1所述的多核平臺下串行程序運行時的自動并行化加速方法,其特征是,第四步中所述的進度校驗,是:重新讀取指令Ic,當指令Ic不在集合Sp中時,清空集合Sp,然后從指令Ic開始追蹤;當指令Ic在集合Sp中、線程P走向該循環(huán)且線程P已經(jīng)開始執(zhí)行該循環(huán),則選取循環(huán)接收后第一條語句作為待分析指令,并清空集合Sp;當指令Ic在集合Sp中、線程P走向該循環(huán)且線程P未執(zhí)行該循環(huán),則對該循環(huán)進行替換處理;當指令Ic在集合Sp中但線程P未走向該循環(huán)時,則刪除集合Sp中Ic以前的指令記錄,并繼續(xù)追蹤。
7.根據(jù)權利要求6所述的多核平臺下串行程序運行時的自動并行化加速方法,其特征是,所述的替換處理,包括以下步驟:
1)當循環(huán)的總工作量大于閾值G時,生成并行化執(zhí)行該循環(huán)的代碼,執(zhí)行該循環(huán)的代碼出口語句跳轉到原循環(huán)出口對應的語句,且將新生成的代碼單獨放在一個或若干個內(nèi)存頁中;否則,放棄替換該循環(huán),并刪除集合Sp中Ic以前的指令記錄,繼續(xù)追蹤;
2)生成代碼后,進行進度校驗,當通過進度校驗時則中斷線程P,且中斷線程P后再次進行校驗,再次通過進度校驗后,執(zhí)行3);否則,線程P繼續(xù)運行;
3)將1)生成的代碼所在的內(nèi)存頁分配給線程P,并修改原循環(huán)起始地址的二進制代碼為跳轉到新生成代碼的起始位置,在集合Sp中刪除原循環(huán)對應指令,加入新生成的代碼指令;
4)替換完成后通知線程P繼續(xù)執(zhí)行,繼續(xù)分析后續(xù)代碼。
8.根據(jù)權利要求7所述的多核平臺下串行程序運行時的自動并行化加速方法,其特征是,所述的閾值G是單個CPU核1秒鐘執(zhí)行的最大指令數(shù)。
9.根據(jù)權利要求7所述的多核平臺下串行程序運行時的自動并行化加速方法,其特征是,所述的通過進度校驗是指:指令Ic在集合Sp中、線程P走向該循環(huán)且線程P未執(zhí)行該循環(huán)。
二十一世紀以來,隨著芯片功耗的不斷提升和芯片復雜度的不斷提升,通過提升頻率等方法來提高單核處理器的性能變得非常困難。單芯片多處理器(Chip Multiprocessor,即CMP)技術成為了新的發(fā)展熱點。截至2010年8月,使用CMP技術的處理器已經(jīng)占據(jù)了大部分市場,從大型商用機型,到普通桌面機,再到嵌入式系統(tǒng),無論高端低端,CMP都成為了各領域處理器結構的必然選擇。
然而CMP的使用并不是應用驅動的,它的出現(xiàn)主要是為了有效地利用新制造工藝帶來的更多的晶體管。由于功耗和驗證難度的限制,已經(jīng)難以通過設計更復雜的單核來提升處理器的性能。與此同時傳統(tǒng)的圖靈機串行程序模型和串行地址空間結構并沒有發(fā)生本質(zhì)改變,原有的大量程序和許多新增的程序依然遵循傳統(tǒng)的設計方法,導致串行化的程序并不能很好的利用2010年可并行執(zhí)行的物理結構以提高性能。
2010年之前技術中采用傳統(tǒng)的并行程序設計方法重寫已有的程序,該方法好像非常簡單,但是事實上并不可行。常用的并行化庫和編譯指令主要有OpenMP(共享存儲并行設計的庫)和MPI(消息傳遞并行編程環(huán)境)。它們一方面難于掌握:并行程序的設計與調(diào)試都比串行程序要困難很多;另一方面也不是特別適用于多核環(huán)境。由于編寫單個并行程序代價就很高,要想把已有的各種應用程序都重寫,實際上是不可能的。
經(jīng)對2010年之前文獻檢索發(fā)現(xiàn),中國專利申請?zhí)枮椋?00510026587.4,名稱為:用戶指導的程序半自動并行化方法,該技術提出了一種使用較為簡單的模型開發(fā)并行化程序,能減小開發(fā)并行程序的復雜度。但是,其使用范圍有限而且仍然需要大量精力進行重新開發(fā),不能很好地解決大量已有的串行程序的問題。
另外一種方法是對串行程序進行自動分析翻譯,生成并行化程序,即線程級推測(ThreadLevel Speculation,即TLS)技術。使用該技術可以使用相應的自動并行化工具,通過對原有串行程序的源代碼、中間代碼或者二進制代碼的分析,自動劃分線程,并生成并行化代碼。該方法雖然可以不用重寫程序,但還是需要對原有的代碼進行重新編譯,這就要求用戶有能力進行代碼重新編譯或者要求用戶更換為已經(jīng)重新編譯的程序,這一要求在一般情況下是不成立的。同時,使用推測技術,雖然在一定程度上提高了并行度,但同時也增加了硬件設計的復雜度,并且在推測級數(shù)較多時推測成功率很低。
多核平臺下串行程序運行時的自動并行化加速方法常見問題
-
回答:圖形算量運行時出現(xiàn)錯誤,總是出現(xiàn)External exception 80000003,應該是程序出現(xiàn)錯誤,建議重新安裝軟件即可解決
-
74LS164是一個串行輸入、8位并行輸出的移位寄存器。并帶有清除端。 74LS595可以串行輸入、8位并行輸出,并帶有鎖存功能, 要實現(xiàn)16位數(shù)據(jù)串入并出,可以用2片8位的以上芯片級聯(lián)實現(xiàn)。
-
你先加入你們南通的廣聯(lián)達官方群,請求修復軟件,你的軟件程序損壞了,
多核平臺下串行程序運行時的自動并行化加速方法專利目的
《多核平臺下串行程序運行時的自動并行化加速方法》的目的在于提供一種多核平臺下串行程序運行時的自動并行化加速方法。該發(fā)明新增可共享讀取的程序計數(shù)器寄存器組,并在操作系統(tǒng)中建立自動并行加速線程,選擇一個線程作為加速的對象,然后實時地分析此線程將要執(zhí)行到的指令代碼,并對其中執(zhí)行循環(huán)的指令代碼進行修改,達到使被加速線程自動并行執(zhí)行的目的。
多核平臺下串行程序運行時的自動并行化加速方法技術方案
《多核平臺下串行程序運行時的自動并行化加速方法》包括以下步驟:
第一步,建立一個共享讀取的程序計數(shù)寄存器組SPC,該寄存器組中寄存器的個數(shù)與CPU核的數(shù)目相同,每個寄存器分別與對應的CPU核相連以實時地儲存該CPU核的程序計數(shù)器值。
所述的共享讀取是:每個CPU核實時讀取寄存器組中每個寄存器存儲的其它CPU核的程序計數(shù)器值。
第二步,當存在空閑的CPU核時,進行加速對象選擇處理,得到自動并行加速線程的加速對象為線程P。
所述的加速對象選擇處理,是:當正在運行且未被加速的用戶線程中存在CPU占用率最高的線程時,則選擇該線程作為自動并行加速線程的加速對象;否則,時間t后,再次選擇正在運行且未被加速的用戶線程中CPU占用率最高的線程作為自動并行加速線程的加速對象,直至得到自動并行加速線程的加速對象。
第三步,當線程P存在已分析指令集合Sp時,載入該集合Sp;否則,為線程P新建一個集合Sp,對線程P所在的CPU核進行讀取處理,得到線程P所在的CPU核當前正在讀取的指令Ic,并由Ic追蹤線程P下一條將要執(zhí)行指令的地址,將追蹤分析的指令代碼和跳轉關系加入集合Sp中。
所述的讀取處理,是:讀取線程P所在的CPU核的程序計數(shù)寄存器的值,將得到的虛擬地址轉換為物理地址,然后從該物理地址得到線程P所在的CPU核正在執(zhí)行的指令Ic,當集合Sp中包括指令Ic時,刪除集合Sp中Ic以前的指令記錄,并根據(jù)集合Sp追蹤線程P下一條將要執(zhí)行的指令;否則,清空集合Sp。
第四步,采用第三步的方法,得到線程P將要執(zhí)行的所有指令,當集合Sp中每次加入條件轉移指令后且集合Sp中存在循環(huán)代碼時,進行進度校驗和替換處理。
所述的進度校驗,是:重新讀取指令Ic,當指令Ic不在集合Sp中時,清空集合Sp,然后從指令Ic開始追蹤;當指令Ic在集合Sp中、線程P走向該循環(huán)且線程P已經(jīng)開始執(zhí)行該循環(huán),則選取循環(huán)接收后第一條語句作為待分析指令,并清空集合Sp;當指令Ic在集合Sp中、線程P走向該循環(huán)且線程P未執(zhí)行該循環(huán),則對該循環(huán)進行替換處理;當指令Ic在集合Sp中但線程P未走向該循環(huán)時,則刪除集合Sp中Ic以前的指令記錄,并繼續(xù)追蹤。
所述的替換處理,包括以下步驟:
1)當循環(huán)的總工作量大于閾值G時,生成并行化執(zhí)行該循環(huán)的代碼,執(zhí)行該循環(huán)的代碼出口語句跳轉到原循環(huán)出口對應的語句,且將新生成的代碼單獨放在一個或若干個內(nèi)存頁中;否則,放棄替換該循環(huán),并刪除集合Sp中Ic以前的指令記錄,繼續(xù)追蹤;
2)生成代碼后,進行進度校驗,當通過進度校驗時則中斷線程P,且中斷線程P后再次進行校驗,再次通過進度校驗后,執(zhí)行3);否則,線程P繼續(xù)運行;
3)將1)生成的代碼所在的內(nèi)存頁分配給線程P,并修改原循環(huán)起始地址的二進制代碼為跳轉到新生成代碼的起始位置,在集合Sp中刪除原循環(huán)對應指令,加入新生成的代碼指令;
4)替換完成后通知線程P繼續(xù)執(zhí)行,繼續(xù)分析后續(xù)代碼。
所述的通過進度校驗是指:指令Ic在集合Sp中、線程P走向該循環(huán)且線程P未執(zhí)行該循環(huán)。
第五步,當線程P被調(diào)度出CPU核時,系統(tǒng)以中斷方式將該事件連同當時的SPCp值發(fā)送給自動并行加速線程,當自動并行加速線程正在替換處理中時,則使用此時的SPCp值作為讀取Ic的依據(jù),繼續(xù)執(zhí)行替換處理直到退出該步驟;否則,自動并行加速線程根據(jù)當時的SPCp值讀取Ic,清空或更新集合Sp,其結果等待線程P被調(diào)入時繼續(xù)使用。
第六步,返回第二步,開始處理新的需要加速的線程。
多核平臺下串行程序運行時的自動并行化加速方法改善效果
與2010年之前的技術相比,《多核平臺下串行程序運行時的自動并行化加速方法》的有益效果是:2010年之前的技術使用不方便,需要重新開發(fā)程序或者重新編譯原來的代碼,而該發(fā)明在運行時對程序進行自動并行,不用對已有程序進行預先的處理,整個過程由操作系統(tǒng)完成,對于用戶完全透明。該發(fā)明能夠在有空閑的CPU核時自動利用空閑資源對程序進行并行加速,免去等待預先處理程序的時間,也省去用戶手動轉換程序的麻煩。
實施例
該實施例包括以下步驟:
第一步,建立一個共享讀取的程序計數(shù)寄存器組SPC,該寄存器組中寄存器的個數(shù)與CPU核的數(shù)目相同,每個寄存器分別與對應的CPU核相連以實時地儲存該CPU核的程序計數(shù)器值。
所述的共享讀取是:每個CPU核實時讀取寄存器組中每個寄存器存儲的其它CPU核的程序計數(shù)器值。
第二步,當存在空閑的CPU核時,進行加速對象選擇處理,得到自動并行加速線程的加速對象為線程P。
所述的加速對象選擇處理,是:當正在運行且未被加速的用戶線程中存在CPU占用率最高的線程時,則選擇該線程作為自動并行加速線程的加速對象;否則,時間t后,再次選擇正在運行且未被加速的用戶線程中CPU占用率最高的線程作為自動并行加速線程的加速對象,直至得到自動并行加速線程的加速對象。
所述的時間t是系統(tǒng)的調(diào)度時間片大小,該實施例為20毫秒。
第三步,當線程P存在已分析指令集合Sp時,載入該集合Sp;否則,為線程P新建一個集合Sp,對線程P所在的CPU核進行讀取處理,得到線程P所在的CPU核當前正在讀取的指令Ic,并由Ic追蹤線程P下一條將要執(zhí)行指令的地址,將追蹤分析的指令代碼和跳轉關系加入集合Sp中。
所述的讀取處理,是:讀取線程P所在的CPU核的程序計數(shù)寄存器的值,將得到的虛擬地址轉換為物理地址,然后從該物理地址得到線程P所在的CPU核正在執(zhí)行的指令Ic,當集合Sp中包括指令Ic時,刪除集合Sp中Ic以前的指令記錄,并根據(jù)集合Sp追蹤線程P下一條將要執(zhí)行的指令;否則,清空集合Sp。
第四步,采用第三步的方法,得到線程P將要執(zhí)行的所有指令,當集合Sp中每次加入條件轉移指令后且集合Sp中存在循環(huán)代碼時,進行進度校驗和替換處理。
所述的進度校驗,是:重新讀取指令Ic,當指令Ic不在集合Sp中時,清空集合Sp,然后從指令Ic開始追蹤;當指令Ic在集合Sp中、線程P走向該循環(huán)且線程P已經(jīng)開始執(zhí)行該循環(huán),則選取循環(huán)接收后第一條語句作為待分析指令,并清空集合Sp;當指令Ic在集合Sp中、線程P走向該循環(huán)且線程P未執(zhí)行該循環(huán),則對該循環(huán)進行替換處理;當指令Ic在集合Sp中但線程P未走向該循環(huán)時,則刪除集合Sp中Ic以前的指令記錄,并繼續(xù)追蹤。
所述的替換處理,包括以下步驟:
1)當循環(huán)的總工作量大于閾值G時,生成并行化執(zhí)行該循環(huán)的代碼,執(zhí)行該循環(huán)的代碼出口語句跳轉到原循環(huán)出口對應的語句,且將新生成的代碼單獨放在一個或若干個內(nèi)存頁中;否則,放棄替換該循環(huán),并刪除集合Sp中Ic以前的指令記錄,繼續(xù)追蹤;
2)生成代碼后,進行進度校驗,當通過進度校驗時則中斷線程P,且中斷線程P后再次進行校驗,再次通過進度校驗后,執(zhí)行3);否則,線程P繼續(xù)運行;
3)將1)生成的代碼所在的內(nèi)存頁分配給線程P,并修改原循環(huán)起始地址的二進制代碼為跳轉到新生成代碼的起始位置,在集合Sp中刪除原循環(huán)對應指令,加入新生成的代碼指令;
4)替換完成后通知線程P繼續(xù)執(zhí)行,繼續(xù)分析后續(xù)代碼。
所述的閾值G是單個CPU核1秒鐘執(zhí)行的最大指令數(shù)。
所述的通過進度校驗是指:指令Ic在集合Sp中、線程P走向該循環(huán)且線程P未執(zhí)行該循環(huán)。
第五步,當線程P被調(diào)度出CPU核時,系統(tǒng)以中斷方式將該事件連同當時的SPCp值發(fā)送給自動并行加速線程,當自動并行加速線程正在替換處理中時,則使用此時的SPCp值作為讀取Ic的依據(jù),繼續(xù)執(zhí)行替換處理直到退出該步驟;否則,自動并行加速線程根據(jù)當時的SPCp值讀取Ic,清空或更新集合Sp,其結果等待線程P被調(diào)入時繼續(xù)使用。
第六步,返回第二步,開始處理新的需要加速的線程。
該實施例方法實現(xiàn)簡單,且完全由操作系統(tǒng)完成;能夠在有空閑的CPU核時自動利用空閑資源對程序進行并行加速,免去等待預先處理程序的時間,從而大大提高了多核平臺下串行程序運行時的并行處理速度。
2020年7月14日,《多核平臺下串行程序運行時的自動并行化加速方法》獲得第二十一屆中國專利獎優(yōu)秀獎。
多核平臺下串行程序運行時的自動并行化加速方法文獻

 C程序內(nèi)存安全的運行時檢測方法研究和實現(xiàn)
C程序內(nèi)存安全的運行時檢測方法研究和實現(xiàn)
格式:pdf
大小:408KB
頁數(shù): 5頁
評分: 4.3
隨著軟件規(guī)模的不斷增大,如何保證軟件的可靠性和安全性成為學術界和工業(yè)界越來越關注的問題.然而由于C語言自身缺乏邊界檢測的機制,使得它不能確保軟件的可靠性與安全性.當前的檢測方法都或多或少存在問題,如不兼容、不完整等.設計了一種完整的C程序內(nèi)存安全的運行時檢測方法,能確保C程序的時間內(nèi)存安全和空間內(nèi)存安全.本文是采用基于指針方法,并且借助開源編譯器clang實現(xiàn)了確保C程序內(nèi)存安全的運行時驗證工具TASSafe.通過實驗證明我們的工具是有效并且是高效的.
 空調(diào)系統(tǒng)在惡劣工況下運行時調(diào)節(jié)方法探討
空調(diào)系統(tǒng)在惡劣工況下運行時調(diào)節(jié)方法探討
格式:pdf
大小:408KB
頁數(shù): 4頁
評分: 4.8
針對目前空調(diào)設計中旁通方案的分析比較,提出了常規(guī)旁通方案存在的弊端,最后通過新型旁通方案的試驗分析,說明新型旁通方案對提高機組的穩(wěn)定性、可靠性有顯著的效果。
在計算機中,數(shù)據(jù)傳輸?shù)姆绞接袃煞N,一種就是串行通訊,每個字符的二進制位按位排列進行傳輸,速度慢,但傳輸距離相對較遠,鼠標口和USB口都是串行端口;另一種是并行通訊,每個字符的二進制位使用多條數(shù)據(jù)線同時進行傳輸,傳輸速度相對要快些,但傳輸距離相對不能太遠,計算機內(nèi)部數(shù)據(jù)傳輸一般都是采用這種方法,標準打印口是屬并行端口。
簡單地說,串行ATA (Serial ATA)是一種采用連續(xù)串行數(shù)據(jù)傳輸方式的硬盤接口新標準,作為新一代的接口規(guī)范,它有望替代我們所用的并行ATA接口。
我們所見到的內(nèi)置硬盤、CD-ROM、DVD-ROM、刻錄機等IDE設備,采用的大多是并行ATA(Parallel ATA)接口,包括常見的Ultra ATA/33/66/100以及最新的Ultra ATA/133標準。幾年來,隨著硬盤設計和制造技術的不斷進步,在外部接口數(shù)據(jù)傳輸率提升的同時,硬盤的內(nèi)部數(shù)據(jù)傳輸率也在不斷提高。采用ATA-3接口的昆騰FireBall EL六代硬盤的內(nèi)部傳輸率僅為20MB/s;而采用ATA-4接口的邁拓鉆石十代(DiamondMax Plus 40)硬盤則提高到43.02MB/s;采用ATA-5接口的希捷酷魚ATA Ⅳ硬盤,更是高達69.3MB/s。從硬盤性能的提升速度來看,在2001年如果還沒有新型IDE硬盤接口推出,將會出現(xiàn)一個危險區(qū),即硬盤的內(nèi)部數(shù)據(jù)傳輸率會超過外部接口所能支持的最大數(shù)據(jù)傳輸率.
即使不考慮硬盤內(nèi)部數(shù)據(jù)傳輸率,單就硬盤的接口數(shù)據(jù)傳輸率而言,其技術潛力也是非常有限的。自ATA/66起硬盤的接口電纜也一直沒有變化過,都是采用40針80芯的。隨著并行ATA接口的不斷提速,電纜之間的電磁干擾越來越嚴重,硬盤數(shù)據(jù)信號在高速傳輸中的信號串擾制約著接口速度的提升。在40針80芯并行電纜上的速度極限到底有多大?硬盤業(yè)內(nèi)專家普遍認為大約是200MB/s。這還只是理論上的極限值,由于損耗的原因實際上能夠達到的接口速度只有理論值的70%左右,外部數(shù)據(jù)傳輸率成為硬盤速度瓶頸的那一天很可能會更早到來。
硬件廠商當然不會坐等這一天的到來而無所作為,他們的解決辦法就是推出新的串行ATA(Serial ATA)規(guī)范。串行ATA最早是在2000年秋季的Intel開發(fā)者論壇上(IDF Fall 2000)提出的,一年多后的IDF Fall 2001上,“串行ATA工作組”正式確立了Serial ATA 1.0標準。2100433B
串行通信是指使用一條數(shù)據(jù)線,將數(shù)據(jù)一位一位地依次傳輸,每一位數(shù)據(jù)占據(jù)一個固定的時間長度。其只需要少數(shù)幾條線就可以在系統(tǒng)間交換信息,特別使用于計算機與計算機、計算機與外設之間的遠距離通信。
終端與其他設備(例如其他終端、計算機和外部設備)通過數(shù)據(jù)傳輸進行通信。數(shù)據(jù)傳輸可以通過兩種方式進行:并行通信和串行通信。
在計算機和終端之間的數(shù)據(jù)傳輸通常是靠電纜或信道上的電流或電壓變化實現(xiàn)的。如果一組數(shù)據(jù)的各數(shù)據(jù)位在多條線上同時被傳輸,這種傳輸方式稱為并行通信。
并行通信時數(shù)據(jù)的各個位同時傳送,可以字或字節(jié)為單位并行進行。并行通信速度快,但用的通信線多、成本高,故不宜進行遠距離通信。計算機或plc各種內(nèi)部總線就是以并行方式傳送數(shù)據(jù)的。另外,在PLC底板上,各種模塊之間通過底板總線交換數(shù)據(jù)也以并行方式進行。
并行通信傳輸中有多個數(shù)據(jù)位,同時在兩個設備之間傳輸。發(fā)送設備將這些數(shù)據(jù)位通過 對應的數(shù)據(jù)線傳送給接收設備,還可附加一位數(shù)據(jù)校驗位。接收設備可同時接收到這些數(shù)據(jù),不需要做任何變換就可直接使用。并行方式主要用于近距離通信。計算 機內(nèi)的總線結構就是并行通信的例子。這種方法的優(yōu)點是傳輸速度快,處理簡單。

串行數(shù)據(jù)傳輸時,數(shù)據(jù)是一位一位地在通信線上傳輸?shù)模扔删哂袔孜豢偩€的計算機內(nèi)的發(fā)送設備,將幾位并行數(shù)據(jù)經(jīng)并--串轉換硬件轉換成串行方式,再逐位經(jīng) 傳輸線到達接收站的設備中,并在接收端將數(shù)據(jù)從串行方式重新轉換成并行方式,以供接收方使用。串行數(shù)據(jù)傳輸?shù)乃俣纫炔⑿袀鬏斅枚啵珜τ诟采w面極其廣 闊的公用電話系統(tǒng)來說具有更大的現(xiàn)實意義。
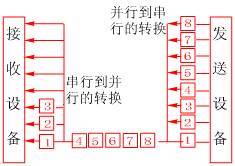
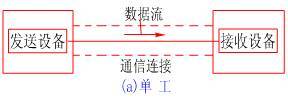
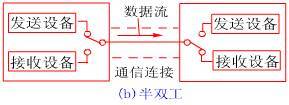
串行數(shù)據(jù)通信的方向性結構有三種,即單工、半雙工和全雙工。

1988年,美國國防分析研究所(IDA)以武器生產(chǎn)為背景, 對傳統(tǒng)的生產(chǎn)模式進行了分析,首次系統(tǒng)化地提出了并行工程的概念。幾年來,并行工程在美國及西方許多國家十分盛行,已成為制造自動化的一個熱點。
90年代是信息時代,更確切地說是知識的時代。大量新知識的產(chǎn)生,促使新知識的應用的更迭周期越來越短,技術的發(fā)展越來越快。如何利用這些技術提供的可能性,抓住用戶心理,加速新產(chǎn)品的構思及概念的形成,并以最短的時間開發(fā)出高質(zhì)量及價格能被用戶接受的產(chǎn)品,已成為市場競爭的焦點。而這一焦點的核心是產(chǎn)品的上市時間。并行工程作為加速新產(chǎn)品開發(fā)過程的綜合手段迅速獲得了推廣,并行工程已成為90年代制造企業(yè)在競爭中贏得生存和發(fā)展的重要手段。
并行工程是集成地、并行地設計產(chǎn)品及相關過程, 包括制造過程和支持過程的系統(tǒng)化方法。這種方法要求開發(fā)人員在設計一開始就考慮產(chǎn)品整個生命周期從概念形成到產(chǎn)品報廢處理的所有因素,包括質(zhì)量、成本、進度計劃和用戶要求,而不是已經(jīng)做到哪一步,再考慮下一步怎么走。
傳統(tǒng)的產(chǎn)品開發(fā)模式為功能部門制,信息共享存在障礙;串行的流程,設計早期不能全面考慮產(chǎn)品生命周期中的各種因素;以基于圖紙的手工設計為主,設計表達存在二義性,缺少先進的計算機平臺,不足以支持協(xié)同化產(chǎn)品開發(fā)。全球化大市場的形成,要求企業(yè)必須改變經(jīng)營策略:提高產(chǎn)品開發(fā)能力、增強市場開拓能力,但傳統(tǒng)的產(chǎn)品開發(fā)模式已不能滿足激烈的市場競爭要求,因而提出了并行工程的思想。并行工程是一種企業(yè)組織、管理和運行的先進設計、制造模式;是采用多學科團隊和并行過程的集成化產(chǎn)品開發(fā)模式。它把傳統(tǒng)的制造技術與計算機技術、系統(tǒng)工程技術和自動化技術相結合,在產(chǎn)品開發(fā)的早期階段全面考慮產(chǎn)品生命周期中的各種因素,力爭使產(chǎn)品開發(fā)能夠一次獲得成功。從而縮短產(chǎn)品開發(fā)周期、提高產(chǎn)品質(zhì)量、降低產(chǎn)品成本、增強市場競爭能力。一些著名的企業(yè)通過實施并行工程取得了顯著效益,如波音(Boeing)、洛克希德(Lockheed)、雷諾(Renauld)、通用電力(GE)等。
傳統(tǒng)產(chǎn)品開發(fā)過程信息流向單一、固定,以信息集成為特征的CIMS可以支持、滿足這種產(chǎn)品開發(fā)模式的需求。并行產(chǎn)品的設計過程是并發(fā)式的,信息流向是多方向的。只有支持過程集成的CIMS才能滿足并行產(chǎn)品開發(fā)的需求。
并行工程具有以下特點:
●強調(diào)團隊工作(Team work)精神和工作方式;
●強調(diào)設計過程的并行性;
●強調(diào)設計過程的系統(tǒng)性;
●強調(diào)設計過程的快速“短”反饋;
利用并行工程對改造傳統(tǒng)產(chǎn)業(yè)有重要作用,并將對提高中國企業(yè)新產(chǎn)品開發(fā)能力、增強其競爭力具有深遠的意義。
多核平臺下串行程序運行時的自動并行化加速方法相關推薦
- 相關百科
- 相關知識
- 相關專欄
- 多根蘭
- 多模式桿式移動機構
- 多水高嶺石
- 多深度融合感知的多視點視頻聯(lián)合處理與高效編碼
- 多源監(jiān)控視頻大尺度人群異常行為感知研究
- 多燈照明
- 多點式電子測斜儀
- 多點監(jiān)視技術
- 多特噴碼機
- 多特蒙德
- 多環(huán)cxw-130d0b(平板黑玻璃)
- 多球面燃燒室的缸頭及其汽油機
- 多用刀桿尺寸
- 多用途擦拭布
- 多用途樹種
- 多電機冗余系統(tǒng)整體建模及容錯控制策略的研究
- 基于壓電堆驅動器的噴嘴擋板式氣體控制閥
- 電氣工程及其自動化特色專業(yè)建設探索
- 磷銨技術改造五大磷肥工程的建議
- 以大豆油多元醇制備的硬質(zhì)聚氨酯泡沫塑料的性能
- 逆變TIG焊機接觸引弧電路的設計(引弧電路)
- 應用模糊數(shù)學理論對公路工程建設項目方案的綜合評價
- 可替代現(xiàn)有隔熱保溫材料的新型材料
- 以貫穿項目為核心載體的建筑工程技術專業(yè)素材庫建設
- 多逆變器太陽能光伏并網(wǎng)發(fā)電系統(tǒng)的組群控制方法
- 影響萘高效減水劑與普通硅酸鹽水泥適應性的關鍵因素
- 在全縣非煤礦山和危化企業(yè)安全生產(chǎn)工作會議上的講話
- 中國工程造價咨詢業(yè)的發(fā)展趨勢
- 支持并行工程和智能CAPP的制造資源建模技術
- 中共重慶市委重慶市人民政府關于建設平安重慶的決定
- 智能建筑工程報警與電視監(jiān)控系統(tǒng)前端設備的安裝施工
- 在“建筑節(jié)能與居住舒適”專題技術交流會議上的講話
最新詞條
安徽省政采項目管理咨詢有限公司
數(shù)字景楓科技發(fā)展(南京)有限公司
懷化市人民政府電子政務管理辦公室
河北省高速公路京德臨時籌建處
中石化華東石油工程有限公司工程技術分公司
手持無線POS機
廣東合正采購招標有限公司
上海城建信息科技有限公司
甘肅鑫禾國際招標有限公司
燒結金屬材料
齒輪計量泵
廣州采陽招標代理有限公司河源分公司
高鋁碳化硅磚
博洛尼智能科技(青島)有限公司
燒結剛玉磚
深圳市東海國際招標有限公司
搭建香蕉育苗大棚
SF計量單位
福建省中億通招標咨詢有限公司
泛海三江
威海鼠尾草
廣東國咨招標有限公司
Excel 數(shù)據(jù)處理與分析應用大全
甘肅中泰博瑞工程項目管理咨詢有限公司
山東創(chuàng)盈項目管理有限公司
當代建筑大師
拆邊機
廣西北纜電纜有限公司
大山檳榔
上海地鐵維護保障有限公司通號分公司
舌花雛菊
甘肅中維國際招標有限公司
華潤燃氣(上海)有限公司
湖北鑫宇陽光工程咨詢有限公司
GB8163標準無縫鋼管
中國石油煉化工程建設項目部
韶關市優(yōu)采招標代理有限公司
莎草目
建設部關于開展城市規(guī)劃動態(tài)監(jiān)測工作的通知
電梯平層準確度
廣州利好來電氣有限公司
蘇州弘創(chuàng)招投標代理有限公司