機(jī)器學(xué)習(xí)算法框架實(shí)戰(zhàn):Java和Python實(shí)現(xiàn)
《機(jī)器學(xué)習(xí)算法框架實(shí)戰(zhàn):Java和Python實(shí)現(xiàn)》本書作者麥嘉銘 ,由機(jī)械工業(yè)出版社出版發(fā)行。
目錄
- 機(jī)器學(xué)習(xí)算法框架實(shí)戰(zhàn):Java和Python實(shí)現(xiàn)圖書目錄
- 機(jī)器學(xué)習(xí)算法框架實(shí)戰(zhàn):Java和Python實(shí)現(xiàn)造價(jià)信息
- 機(jī)器學(xué)習(xí)算法框架實(shí)戰(zhàn):Java和Python實(shí)現(xiàn)作者簡(jiǎn)介
- 機(jī)器學(xué)習(xí)算法框架實(shí)戰(zhàn):Java和Python實(shí)現(xiàn)內(nèi)容簡(jiǎn)介
- 機(jī)器學(xué)習(xí)算法框架實(shí)戰(zhàn):Java和Python實(shí)現(xiàn)常見問(wèn)題
- 機(jī)器學(xué)習(xí)算法框架實(shí)戰(zhàn):Java和Python實(shí)現(xiàn)文獻(xiàn)
- 機(jī)器學(xué)習(xí):軟件工程方法與實(shí)現(xiàn)內(nèi)容簡(jiǎn)介
- JavaWeb應(yīng)用開發(fā)框架實(shí)例
- 編譯 | 圖解機(jī)器學(xué)習(xí)的基本算法
機(jī)器學(xué)習(xí)算法框架實(shí)戰(zhàn):Java和Python實(shí)現(xiàn)基本信息
| 書????名 | 機(jī)器學(xué)習(xí)算法框架實(shí)戰(zhàn):Java和Python實(shí)現(xiàn) [1]? | 作????者 | 麥嘉銘 |
|---|---|---|---|
| 類????別 | 計(jì)算機(jī)類圖書 | 出版社 | 機(jī)械工業(yè)出版社 |
| 出版時(shí)間 | 2020年7月 [1]? | 頁(yè)????數(shù) | 216 頁(yè) |
| 定????價(jià) | 69 元 | 開????本 | 16 開 |
| 裝????幀 | 平裝 | ISBN | 9787111659754 |
第1篇 緒論
第1章 背景 2
1.1 機(jī)器學(xué)習(xí)的概念 2
1.2 機(jī)器學(xué)習(xí)所解決的問(wèn)題 3
1.3 如何選擇機(jī)器學(xué)習(xí)算法 5
1.4 習(xí)題 5
第2章 機(jī)器學(xué)習(xí)算法框架概要 7
2.1 算法框架的分層模型 7
2.2 分層模型中各層級(jí)的職責(zé) 8
2.3 開始搭建框架的準(zhǔn)備工作 8
第2篇 代數(shù)矩陣運(yùn)算層
第3章 矩陣運(yùn)算庫(kù) 20
3.1 矩陣運(yùn)算庫(kù)概述 20
3.2 矩陣基本運(yùn)算的實(shí)現(xiàn) 20
3.3 矩陣的其他操作 27
3.4 習(xí)題 32
第4章 矩陣相關(guān)函數(shù)的實(shí)現(xiàn) 33
4.1 常用函數(shù) 33
4.2 行列式函數(shù) 41
4.3 矩陣求逆函數(shù) 43
4.4 矩陣特征值和特征向量函數(shù) 44
4.5 矩陣正交化函數(shù) 45
4.6 習(xí)題 49
第3篇 最優(yōu)化方法層
第5章 最速下降優(yōu)化器 52
5.1 最速下降優(yōu)化方法概述 52
5.2 最速下降優(yōu)化器的實(shí)現(xiàn) 54
5.3 一個(gè)目標(biāo)函數(shù)的優(yōu)化例子 62
5.4 習(xí)題 66
第6章 遺傳算法優(yōu)化器 67
6.1 遺傳算法概述 67
6.2 遺傳算法優(yōu)化器的實(shí)現(xiàn) 71
6.3 一個(gè)目標(biāo)函數(shù)的優(yōu)化例子 82
6.4 習(xí)題 85
第4篇 算法模型層
第7章 分類和回歸模型 88
7.1 分類和回歸模型概述 88
7.2 基礎(chǔ)回歸模型 89
7.3 分類回歸分析的例子 102
7.4 習(xí)題 108
第8章 多層神經(jīng)網(wǎng)絡(luò)模型 109
8.1 多層神經(jīng)網(wǎng)絡(luò)模型概述 109
8.2 多層神經(jīng)網(wǎng)絡(luò)模型的實(shí)現(xiàn) 115
8.3 多層神經(jīng)網(wǎng)絡(luò)模型示例 122
8.4 習(xí)題 125
第9章 聚類模型 126
9.1 K-means模型 126
9.2 GMM 134
9.3 習(xí)題 147
第10章 時(shí)間序列模型 148
10.1 指數(shù)平滑模型 148
10.2 Holt-Winters模型 150
10.3 習(xí)題 160
第11章 降維和特征提取 161
11.1 降維的目的 161
11.2 主成分分析模型 162
11.3 自動(dòng)編碼機(jī)模型 170
11.4 習(xí)題 176
第5篇 業(yè)務(wù)功能層
第12章 時(shí)間序列異常檢測(cè) 178
12.1 時(shí)間序列異常檢測(cè)的應(yīng)用場(chǎng)景 178
12.2 時(shí)間序列異常檢測(cè)的基本原理 178
12.3 時(shí)間序列異常檢測(cè)功能服務(wù)的實(shí)現(xiàn) 180
12.4 應(yīng)用實(shí)例:找出數(shù)據(jù)中的異常記錄 182
12.5 習(xí)題 183
第13章 離群點(diǎn)檢測(cè) 184
13.1 離群點(diǎn)檢測(cè)的應(yīng)用場(chǎng)景 184
13.2 離群點(diǎn)檢測(cè)的基本原理 185
13.3 離群點(diǎn)檢測(cè)功能服務(wù)的實(shí)現(xiàn) 188
13.4 應(yīng)用實(shí)例:找出數(shù)據(jù)中的異常記錄 191
13.5 習(xí)題 193
第14章 趨勢(shì)線擬合 194
14.1 趨勢(shì)線擬合的應(yīng)用場(chǎng)景 194
14.2 趨勢(shì)線擬合的基本原理 195
14.3 趨勢(shì)線擬合功能服務(wù)的實(shí)現(xiàn) 196
14.4 應(yīng)用實(shí)例:對(duì)樣本數(shù)據(jù)進(jìn)行趨勢(shì)線擬合 201
14.5 習(xí)題 203
機(jī)器學(xué)習(xí)算法框架實(shí)戰(zhàn):Java和Python實(shí)現(xiàn)造價(jià)信息
麥嘉銘 BIGO公司大數(shù)據(jù)高級(jí)開發(fā)工程師。曾先后于中國(guó)科學(xué)院、新加坡先進(jìn)數(shù)字科學(xué)中心訪學(xué)交流,發(fā)表過(guò)多篇國(guó)際SCI期刊論文,擁有豐富的算法及工程方面的項(xiàng)目開發(fā)經(jīng)驗(yàn)。
隨著互聯(lián)網(wǎng)技術(shù)的飛速發(fā)展,全球逐漸步入大數(shù)據(jù)時(shí)代,智能化的趨勢(shì)越來(lái)越明顯,各行各業(yè)幾乎都喊出了智能化的口號(hào)。機(jī)器學(xué)習(xí)作為人工智能的一個(gè)重要研究方向,在一定程度上成為IT人才的必要技能。本書以一個(gè)自研機(jī)器學(xué)習(xí)算法框架的構(gòu)建為主線,首先介紹了機(jī)器學(xué)習(xí)的相關(guān)概念和背景,然后按照代數(shù)矩陣運(yùn)算層、最優(yōu)化方法層、算法模型層和業(yè)務(wù)功能層的分層順序?qū)λ惴蚣苷归_講述,旨在通過(guò)理論和實(shí)踐相結(jié)合的方式,幫助廣大零算法基礎(chǔ)的開發(fā)人員了解和掌握一定的算法能力,同時(shí)也為算法設(shè)計(jì)人員提供工程實(shí)踐中的參考范例。
本書實(shí)用性強(qiáng),適合零算法基礎(chǔ)的開發(fā)人員閱讀,也適合具備一定算法能力且希望在工程實(shí)踐中有所借鑒的工程技術(shù)人員閱讀。另外,本書還適合作為算法設(shè)計(jì)人員及機(jī)器學(xué)習(xí)算法愛好者的參考書。
機(jī)器學(xué)習(xí)算法框架實(shí)戰(zhàn):Java和Python實(shí)現(xiàn)常見問(wèn)題
-
誰(shuí)有裝飾算量實(shí)戰(zhàn)學(xué)習(xí)資料
已發(fā)送,請(qǐng)注意查收一下。收到請(qǐng)采納一下,您的采納將是我們更優(yōu)質(zhì)回答問(wèn)題的動(dòng)力,謝謝。若有疑問(wèn)請(qǐng)聯(lián)系郵箱:378458003@qq.com (發(fā)郵件過(guò)來(lái)即可)
-
Python是腳本語(yǔ)言,解釋執(zhí)行,不需要編譯。pyc是為了提高效率。就知道這么多。
-
因?yàn)槟愕谝豢绾偷谌绮荒艿倪叺闹咏孛娴膶挾缺戎卞^的長(zhǎng)度小,所以就要那樣算了。這是正確的~~~
機(jī)器學(xué)習(xí)算法框架實(shí)戰(zhàn):Java和Python實(shí)現(xiàn)文獻(xiàn)

 框架式動(dòng)力機(jī)器荷載探討
框架式動(dòng)力機(jī)器荷載探討
格式:pdf
大小:271KB
頁(yè)數(shù): 3頁(yè)
評(píng)分: 4.6
針對(duì)冶金行業(yè)經(jīng)常用的大型動(dòng)力機(jī)器(空氣壓縮機(jī),鼓風(fēng)機(jī),電機(jī),汽輪機(jī)),結(jié)合國(guó)內(nèi)外的規(guī)范,對(duì)國(guó)內(nèi)外廠家的資料進(jìn)行了研究。討論了框架式動(dòng)力機(jī)器基礎(chǔ)設(shè)計(jì)荷載取值及組合等問(wèn)題,解決了基礎(chǔ)設(shè)計(jì)時(shí)的一些難題。
隨機(jī)森林機(jī)器學(xué)習(xí)算法在橋梁檢測(cè)中的應(yīng)用
格式:pdf
大小:271KB
頁(yè)數(shù): 2頁(yè)
評(píng)分: 4.8
在當(dāng)下交通運(yùn)輸業(yè)的飛速發(fā)展,我國(guó)公路橋梁的面臨著交通負(fù)載不斷增長(zhǎng)的情況.因而需不斷更新橋梁檢測(cè)技術(shù)及方法,提高對(duì)檢測(cè)數(shù)據(jù)的認(rèn)識(shí),知識(shí)轉(zhuǎn)化,從而對(duì)橋梁的實(shí)際狀況有更加深入的理解.監(jiān)測(cè)工作中產(chǎn)生的大規(guī)模數(shù)據(jù)有待利用處理,有效挖掘.文章對(duì)福建省三明市、南平市公路橋檢測(cè)的數(shù)據(jù)進(jìn)行了清洗,引入機(jī)器學(xué)習(xí)算法中的隨機(jī)森林算法,對(duì)檢測(cè)數(shù)據(jù)進(jìn)行了人工智能處理,并與專家評(píng)測(cè)結(jié)果進(jìn)行對(duì)比分析,證明了機(jī)器學(xué)習(xí)算法在橋梁檢測(cè)監(jiān)控的可行性.
這是一部指導(dǎo)讀者如何將軟件工程的思想、方法、工具和策略應(yīng)用到機(jī)器學(xué)習(xí)實(shí)踐中的著作。
作者融合了自己10年的工程實(shí)踐經(jīng)驗(yàn),以Python為工具,詳細(xì)闡述機(jī)器學(xué)習(xí)核心概念、原理和實(shí)現(xiàn),并提供了數(shù)據(jù)分析和處理、特征選擇、模型調(diào)參和大規(guī)模模型上線系統(tǒng)架構(gòu)等多個(gè)高質(zhì)量源碼包和工業(yè)應(yīng)用框架,旨在幫助讀者提高代碼的設(shè)計(jì)質(zhì)量和機(jī)器學(xué)習(xí)項(xiàng)目的工程效率。
全書共16章,分為4個(gè)部分:
第一部分 工程基礎(chǔ)篇(1~3章)
介紹了機(jī)器學(xué)習(xí)和軟件工程的融合,涉及理論、方法、工程化的數(shù)據(jù)科學(xué)環(huán)境和數(shù)據(jù)準(zhǔn)備;
第二部分 機(jī)器學(xué)習(xí)基礎(chǔ)篇(4、5章)
講述了機(jī)器學(xué)習(xí)建模流程、核心概念,數(shù)據(jù)分析方法;
第三部分 特征篇(6~8章)
詳細(xì)介紹了多種特征離散化方法和實(shí)現(xiàn)、特征自動(dòng)衍生工具和自動(dòng)化的特征選擇原理與實(shí)現(xiàn);
第四部分 模型篇(9~16章)
首先,深入地剖析了線性模型、樹模型和集成模型的原理,以及模型調(diào)參方法、自動(dòng)調(diào)參、模型性能評(píng)估和模型解釋等;然后,通過(guò)5種工程化的模型上線方法講解了模型即服務(wù);最后,講解了模型的穩(wěn)定性監(jiān)控的方法與實(shí)現(xiàn),這是機(jī)器學(xué)習(xí)項(xiàng)目的最后一環(huán)。

JavaWeb應(yīng)用開發(fā)框架實(shí)例
一、 概述
Web 應(yīng)用架構(gòu)可以劃分為兩大子系統(tǒng):前端子系統(tǒng)和后臺(tái)子系統(tǒng)。
前端子系統(tǒng):
1. 基礎(chǔ)技術(shù): Html/Java/CSS / Flash
2. 開發(fā)框架: jQuery, Extjs , Flex 等;
后臺(tái)子系統(tǒng):
1. 基礎(chǔ)技術(shù): Java Servlet;
2. 開發(fā)框架: Struts, Spring, Hibernate, ibatis 等;
3. 應(yīng)用服務(wù)器: Tomcat / Jetty
編程模型: B/S 模型。 客戶端向服務(wù)器端發(fā)送請(qǐng)求, 服務(wù)器經(jīng)過(guò)處理后返回響應(yīng), 然后客戶端根據(jù)響應(yīng)及需求繪制前端展現(xiàn)。
在用戶客戶端和實(shí)際提供功能的Web 服務(wù)器之間還可能存在著代理服務(wù)器, 負(fù)載均衡服務(wù)器, 不過(guò)那些屬于錦上添花的事物,暫時(shí)不在考慮范圍內(nèi)。
客戶端應(yīng)用理念: 客戶端承擔(dān)大量的交互邏輯及渲染工作,服務(wù)器端主要是處理請(qǐng)求和返回?cái)?shù)據(jù)。
前后端系統(tǒng)耦合: 客戶端和服務(wù)器端各自處理自己內(nèi)部的子系統(tǒng)耦合;而客戶端與服務(wù)器端的耦合簡(jiǎn)化為一個(gè)通信與數(shù)據(jù)通道。該通道用來(lái)傳輸通信請(qǐng)求和返回?cái)?shù)據(jù)。
請(qǐng)求通信: 采用 Http / Tcp 協(xié)議
數(shù)據(jù)通道: 采用 Json, xml , 文本字符串,字節(jié)。 內(nèi)部系統(tǒng)一般采用 Json 作為數(shù)據(jù)交換格式;系統(tǒng)間的互操作則采用XML 來(lái)規(guī)范;文本字符串是最一般的形式, 字節(jié)是最底層的形式。
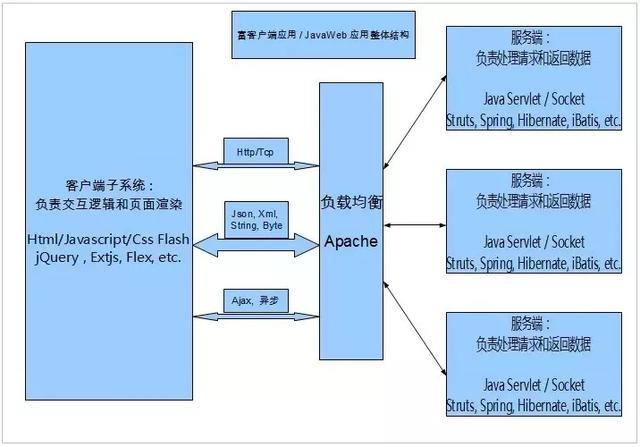
JavaWeb應(yīng)用開發(fā)框架實(shí)例
二、 架構(gòu)演變
最輕的架構(gòu): jQuery + Servlet + ajax 在客戶端使用 jQuery發(fā)送 ajax 請(qǐng)求給Java 服務(wù)端的 Servlet 進(jìn)行處理, Servlet 僅僅返回?cái)?shù)據(jù)給客戶端進(jìn)行渲染。
該架構(gòu)有效地分離了前端展示和后臺(tái)請(qǐng)求處理,同時(shí)又保持了最輕的復(fù)雜性, 只需要學(xué)會(huì)編寫 Servlet 及使用 jQuery , 就能構(gòu)建簡(jiǎn)單的應(yīng)用。
如果只是做個(gè)人創(chuàng)意演示, 可以采用該架構(gòu), 快速實(shí)現(xiàn)自己的創(chuàng)意功能。 Servlet 是Java web 應(yīng)用的基礎(chǔ)技術(shù),jQuery 則是前端開發(fā)的簡(jiǎn)單易用的利器。
后臺(tái)架構(gòu)演變:
1. 邏輯與頁(yè)面的分離: JSP/Servlet
JSP 實(shí)現(xiàn)了頁(yè)面邏輯與外觀的分離,但是, 前端子系統(tǒng)與后臺(tái)子系統(tǒng)仍然是緊密耦合的; 前端設(shè)計(jì)人員實(shí)際上只需要服務(wù)端返回的數(shù)據(jù), 就可設(shè)計(jì)出非常專業(yè)的界面顯示。
2. MVC 架構(gòu):Struts2(含Servlet,MVC) + JDBC
用Servlet 來(lái)添加服務(wù)器功能是基本的選擇,但在web.xml中配置大量的 Servlet 卻不是最佳的選擇。
Struts2 在服務(wù)端實(shí)現(xiàn)了更豐富的MVC 模式, 將本來(lái)由應(yīng)用決定的控制器從web容器中分離。
3. SSH 架構(gòu): Struts2(含Servlet, MVC) + Spring (Ioc) + Hibernate (ORM,對(duì)象-關(guān)系映射)
通常, 應(yīng)用系統(tǒng)中需要預(yù)先創(chuàng)建一些單例對(duì)象, 比如 Controller, Service, Dao, 線程池等, 可以引入 Spring Ioc 來(lái)有效地創(chuàng)建、管理和推送這些對(duì)象;使用 Hibernate 來(lái)實(shí)現(xiàn)關(guān)系數(shù)據(jù)庫(kù)的行與面向?qū)ο蟮膶傩灾g的映射與聯(lián)接,以更好地簡(jiǎn)化和管理應(yīng)用系統(tǒng)的數(shù)據(jù)庫(kù)操作。SSH 可以說(shuō)是 JavaWeb應(yīng)用系統(tǒng)開發(fā)的三劍客。
4. SI 架構(gòu): SpringMVC(含Servlet, Ioc, MVC, Rest) + iBatis (Semi-ORM)
過(guò)于復(fù)雜的架構(gòu)會(huì)將人搞暈。因此,在適應(yīng)需求的情況下, 盡量選擇簡(jiǎn)單的架構(gòu),是明智之選。 這種架構(gòu)使用面向資源的理念,著重使用Spring作為MVC及應(yīng)用基礎(chǔ)服務(wù)設(shè)施, 同時(shí)使用 iBatis 來(lái)實(shí)現(xiàn)更簡(jiǎn)單靈活的ORM映射, 使之在可以理解和維護(hù)的范圍內(nèi)。
前端架構(gòu):
1. Flash 架構(gòu): Flex + jQuery + JSP
這是一種比較傳統(tǒng)的前端架構(gòu),采用同步模式, Flex 承擔(dān)大量的頁(yè)面渲染工作, 并采用AMF協(xié)議與Java端進(jìn)行通信, 而JSP 則可以用于更快速的頁(yè)面顯示。優(yōu)點(diǎn)是: 經(jīng)過(guò)考驗(yàn)的結(jié)構(gòu), 通常是值得信賴的; 缺點(diǎn)是, 由于采用同步模式, 在交互效果上可能不夠流暢, 需要進(jìn)行比較耗時(shí)的編譯過(guò)程;此外, Flex 基于瀏覽器插件運(yùn)行,在調(diào)試方面有些麻煩。
2. MVC 架構(gòu): Extjs + jQuery
這是一種比較現(xiàn)代的前端架構(gòu), 采用異步模式, Extjs4 可以實(shí)現(xiàn)前端子系統(tǒng)的MVC 分離, 對(duì)于可維護(hù)性是非常不錯(cuò)的支持;此外, jQuery 可以作為有效的補(bǔ)充。
優(yōu)點(diǎn): 異步, 快速, 對(duì)于企業(yè)內(nèi)部的后臺(tái)管理系統(tǒng)是非常好的選擇。
缺點(diǎn): Extjs4 的可定制性、可適應(yīng)性可能難以適應(yīng)各種特殊的需求,需要用其它組件來(lái)補(bǔ)充, 比如大數(shù)據(jù)量的繪制。對(duì)于互聯(lián)網(wǎng)應(yīng)用, 速度可能是致命傷。
三、 架構(gòu)的選擇
不要去詢問(wèn)哪種架構(gòu)更好,更需要做的是清晰地定位項(xiàng)目目標(biāo),根據(jù)自己的具體情況來(lái)選擇和定制架構(gòu)。反復(fù)地嘗試、觀察和改進(jìn),反復(fù)磨煉技藝,這樣才有助于設(shè)計(jì)水平的提升。
架構(gòu)的選擇通常有四種關(guān)注點(diǎn):
1. 適用性: 是否適合你的項(xiàng)目需求。 架構(gòu)有大有小, 小項(xiàng)目用小架構(gòu), 大項(xiàng)目用大架構(gòu)。
2. 可擴(kuò)展性: 該架構(gòu)在需要添加新功能時(shí),是否能夠以常量的成本添加到現(xiàn)有系統(tǒng)中, 所做的改動(dòng)在多大程度上會(huì)影響現(xiàn)有功能的實(shí)現(xiàn)(基本不影響,還是要大面積波及)。
3. 便利性: 使用該架構(gòu)是否易于開發(fā)功能和擴(kuò)展功能, 學(xué)習(xí)、開發(fā)和測(cè)試成本有多大。
4. 復(fù)雜性: 使用該架構(gòu)后,維護(hù)起來(lái)的成本有多大。你自然希望能夠?qū)懸粭l語(yǔ)句做很多事,使用各種成熟的組件是正確的方式,同時(shí),在項(xiàng)目中混雜各種組件,也會(huì)提升理解和維護(hù)系統(tǒng)的復(fù)雜度。便利性和復(fù)雜性需要達(dá)到較好的平衡。
特殊的關(guān)注點(diǎn):
譬如,應(yīng)用需要支持高并發(fā)的情況, 需要建立一個(gè)底層的并發(fā)基礎(chǔ)設(shè)施, 并向上層提供簡(jiǎn)單易用的接口,屏蔽其復(fù)雜性。
四、 架構(gòu)演進(jìn)的基本手段
架構(gòu)并不是一成不變的, 在做出最初的架構(gòu)之后,隨著開發(fā)的具體情況和需求的變更, 需要對(duì)最初架構(gòu)做出變更和改進(jìn)。
架構(gòu)演進(jìn)的基本手段:
一致性, 隔離與統(tǒng)一管理, 螺旋式重構(gòu)改進(jìn), 消除重復(fù), 借鑒現(xiàn)有方案。
1. 一致性: 確保使用統(tǒng)一模式來(lái)處理相同或相似的功能; 解決一次, 使用多次。
2. 模塊化、隔離與統(tǒng)一管理: 對(duì)于整體的應(yīng)用, 分而治之,將其劃分為隔離性良好的模塊,提供必要的通信耦合;對(duì)于特定的功能模塊, 采用隔離手段,將其隔離在局部統(tǒng)一管理,避免分散在系統(tǒng)的各處。
3. 不斷重構(gòu)改進(jìn), 一旦發(fā)現(xiàn)更好的方式, 馬上替換掉原有方式。
4. 盡可能重用,消除重復(fù)。
5. 盡可能先借鑒系統(tǒng)中已有方案并復(fù)用之;如果有更好方案可替換之;
有一條設(shè)計(jì)準(zhǔn)則是: 預(yù)先設(shè)計(jì), 但不要過(guò)早設(shè)計(jì)。
意思是說(shuō), 需要對(duì)需求清楚的部分進(jìn)行仔細(xì)的設(shè)計(jì), 但是對(duì)于未知不清楚的需求,要堅(jiān)持去理解它,但不要過(guò)早地去做出“預(yù)測(cè)性設(shè)計(jì)”;設(shè)計(jì)必須是明確的、清晰的、有效的, 不能針對(duì)含糊的東西來(lái)設(shè)計(jì)。可以在后期通過(guò)架構(gòu)演進(jìn)來(lái)獲得對(duì)后續(xù)需求的適應(yīng)能力。
每當(dāng)提到機(jī)器學(xué)習(xí),大家總是被其中的各種各樣的算法和方法搞暈,覺得無(wú)從下手。確實(shí),機(jī)器學(xué)習(xí)的各種套路確實(shí)不少,但是如果掌握了正確的路徑和方法,其實(shí)還是有跡可循的,這里我推薦SAS的Li Hui的這篇博客,講述了如何選擇機(jī)器學(xué)習(xí)的各種方法。
另外,Scikit-learn 也提供了一幅清晰的路線圖給大家選擇:
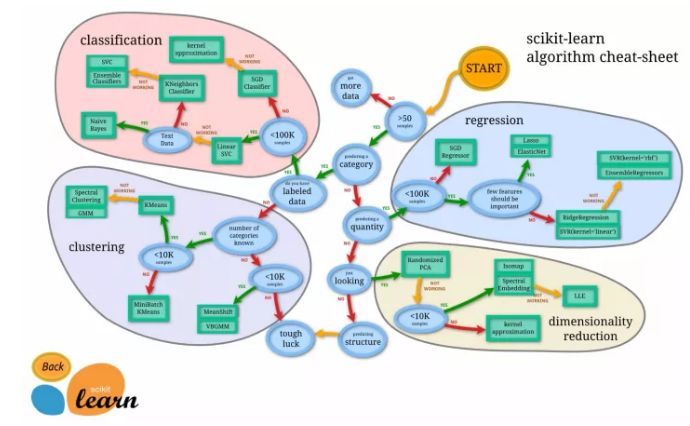
其實(shí)機(jī)器學(xué)習(xí)的基本算法都很簡(jiǎn)單,下面我們就利用二維數(shù)據(jù)和交互圖形來(lái)看看機(jī)器學(xué)習(xí)中的一些基本算法以及它們的原理。(另外向Bret Victor致敬,他的 Inventing on principle 深深的影響了我)
所有的代碼即演示可以在我的Codepen的這個(gè)Collection中找到。
首先,機(jī)器學(xué)習(xí)最大的分支的監(jiān)督學(xué)習(xí)和無(wú)監(jiān)督學(xué)習(xí),簡(jiǎn)單說(shuō)數(shù)據(jù)已經(jīng)打好標(biāo)簽的是監(jiān)督學(xué)習(xí),而數(shù)據(jù)沒(méi)有標(biāo)簽的是無(wú)監(jiān)督學(xué)習(xí)。從大的分類上看,降維和聚類被劃在無(wú)監(jiān)督學(xué)習(xí),回歸和分類屬于監(jiān)督學(xué)習(xí)。
無(wú)監(jiān)督學(xué)習(xí)
如果你的數(shù)據(jù)都沒(méi)有標(biāo)簽,你可以選擇花錢請(qǐng)人來(lái)標(biāo)注你的數(shù)據(jù),或者使用無(wú)監(jiān)督學(xué)習(xí)的方法
首先你可以考慮是否要對(duì)數(shù)據(jù)進(jìn)行降維。
降維
降維顧名思義就是把高維度的數(shù)據(jù)變成為低維度。常見的降維方法有PCA, LDA, SVD等。
主成分分析 PCA
降維里最經(jīng)典的方法是主成分分析PCA,也就是找到數(shù)據(jù)的主要組成成分,拋棄掉不重要的成分。

這里我們先用鼠標(biāo)隨機(jī)生成8個(gè)數(shù)據(jù)點(diǎn),然后繪制出表示主成分的白色直線。這根線就是二維數(shù)據(jù)降維后的主成分,藍(lán)色的直線是數(shù)據(jù)點(diǎn)在新的主成分維度上的投影線,也就是垂線。主成分分析的數(shù)學(xué)意義可以看成是找到這根白色直線,使得投影的藍(lán)色線段的長(zhǎng)度的和為最小值。
聚類
因?yàn)樵诜潜O(jiān)督學(xué)習(xí)的環(huán)境下,數(shù)據(jù)沒(méi)有標(biāo)簽,那么能對(duì)數(shù)據(jù)所做的最好的分析除了降維,就是把具有相同特質(zhì)的數(shù)據(jù)歸并在一起,也就是聚類。
層級(jí)聚類 Hierachical Cluster
該聚類方法用于構(gòu)建一個(gè)擁有層次結(jié)構(gòu)的聚類
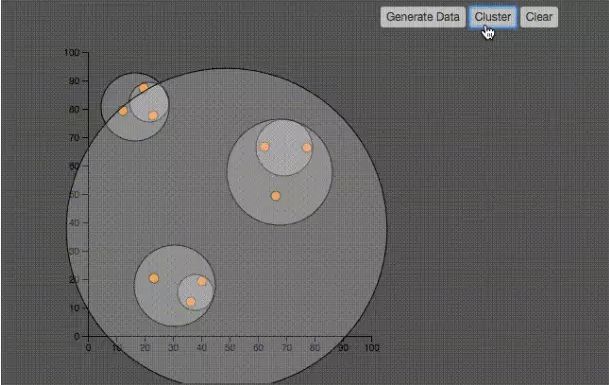
如上圖所示,層級(jí)聚類的算法非常的簡(jiǎn)單:
1、初始時(shí)刻,所有點(diǎn)都自己是一個(gè)聚類
2、找到距離最近的兩個(gè)聚類(剛開始也就是兩個(gè)點(diǎn)),形成一個(gè)聚類
3、兩個(gè)聚類的距離指的是聚類中最近的兩個(gè)點(diǎn)之間的距離
4、重復(fù)第二步,直到所有的點(diǎn)都被聚集到聚類中。
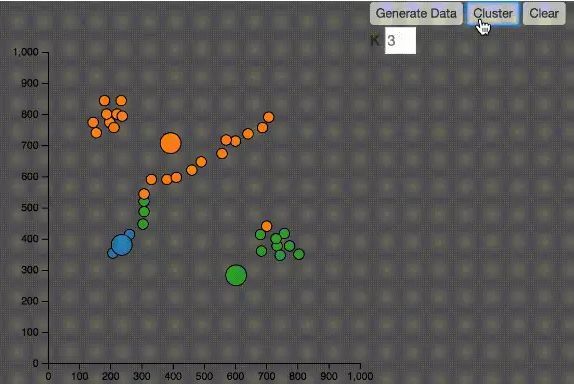
KMeans
KMeans中文翻譯K均值算法,是最常見的聚類算法。
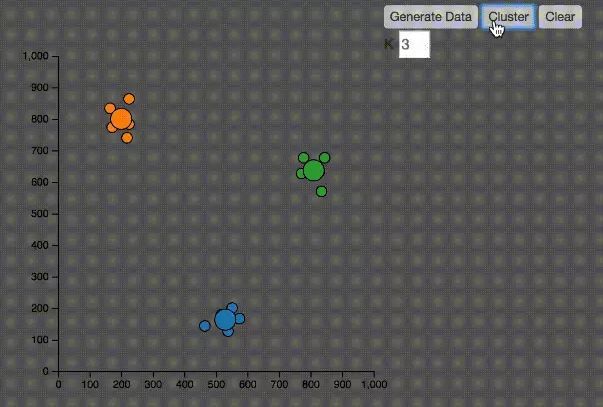
1、隨機(jī)在圖中取K(這里K=3)個(gè)中心種子點(diǎn)。
2、然后對(duì)圖中的所有點(diǎn)求到這K個(gè)中心種子點(diǎn)的距離,假如點(diǎn)P離中心點(diǎn)S最近,那么P屬于S點(diǎn)的聚類。
3、接下來(lái),我們要移動(dòng)中心點(diǎn)到屬于他的“聚類”的中心。
4、然后重復(fù)第2)和第3)步,直到,中心點(diǎn)沒(méi)有移動(dòng),那么算法收斂,找到所有的聚類。
KMeans算法有幾個(gè)問(wèn)題:
1.如何決定K值,在上圖的例子中,我知道要分三個(gè)聚類,所以選擇K等于3,然而在實(shí)際的應(yīng)用中,往往并不知道應(yīng)該分成幾個(gè)類
2.由于中心點(diǎn)的初始位置是隨機(jī)的,有可能并不能正確分類,大家可以在我的Codepen中嘗試不同的數(shù)據(jù)
3.如下圖,如果數(shù)據(jù)的分布在空間上有特殊性,KMeans算法并不能有效的分類。中間的點(diǎn)被分別歸到了橙色和藍(lán)色,其實(shí)都應(yīng)該是藍(lán)色。
DBSCAN
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)中文是基于密度的聚類算法。
DBSCAN算法基于一個(gè)事實(shí):一個(gè)聚類可以由其中的任何核心對(duì)象唯一確定。
算法的具體聚類過(guò)程如下:
1、掃描整個(gè)數(shù)據(jù)集,找到任意一個(gè)核心點(diǎn),對(duì)該核心點(diǎn)進(jìn)行擴(kuò)充。擴(kuò)充的方法是尋找從該核心點(diǎn)出發(fā)的所有密度相連的數(shù)據(jù)點(diǎn)(注意是密度相連)。
2、遍歷該核心點(diǎn)的鄰域內(nèi)的所有核心點(diǎn)(因?yàn)檫吔琰c(diǎn)是無(wú)法擴(kuò)充的),尋找與這些數(shù)據(jù)點(diǎn)密度相連的點(diǎn),直到?jīng)]有可以擴(kuò)充的數(shù)據(jù)點(diǎn)為止。最后聚類成的簇的邊界節(jié)點(diǎn)都是非核心數(shù)據(jù)點(diǎn)。
3、之后就是重新掃描數(shù)據(jù)集(不包括之前尋找到的簇中的任何數(shù)據(jù)點(diǎn)),尋找沒(méi)有被聚類的核心點(diǎn),再重復(fù)上面的步驟,對(duì)該核心點(diǎn)進(jìn)行擴(kuò)充直到數(shù)據(jù)集中沒(méi)有新的核心點(diǎn)為止。數(shù)據(jù)集中沒(méi)有包含在任何簇中的數(shù)據(jù)點(diǎn)就構(gòu)成異常點(diǎn)。
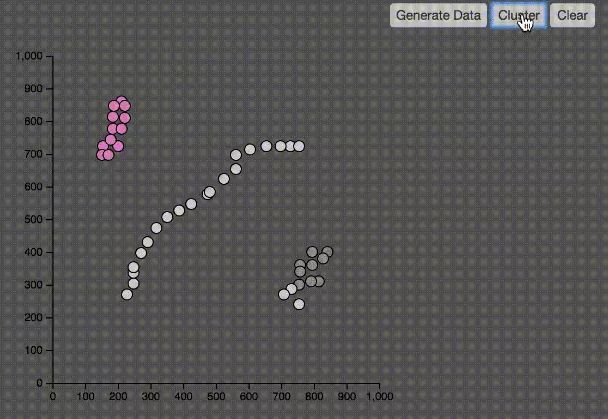
如上圖所示,DBSCAN可以有效的解決KMeans不能正確分類的數(shù)據(jù)集。并且不需要知道K值。
當(dāng)然,DBCSAN還是要決定兩個(gè)參數(shù),如何決定這兩個(gè)參數(shù)是分類效果的關(guān)鍵因素:
1、一個(gè)參數(shù)是半徑(Eps),表示以給定點(diǎn)P為中心的圓形鄰域的范圍;
2、另一個(gè)參數(shù)是以點(diǎn)P為中心的鄰域內(nèi)最少點(diǎn)的數(shù)量(MinPts)。如果滿足:以點(diǎn)P為中心、半徑為Eps的鄰域內(nèi)的點(diǎn)的個(gè)數(shù)不少于MinPts,則稱點(diǎn)P為核心點(diǎn)。
監(jiān)督學(xué)習(xí)
監(jiān)督學(xué)習(xí)中的數(shù)據(jù)要求具有標(biāo)簽。也就是說(shuō)針對(duì)已有的結(jié)果去預(yù)測(cè)新出現(xiàn)的數(shù)據(jù)。如果要預(yù)測(cè)的內(nèi)容是數(shù)值類型,我們稱作回歸,如果要預(yù)測(cè)的內(nèi)容是類別或者是離散的,我們稱作分類。
其實(shí)回歸和分類本質(zhì)上是類似的,所以很多的算法既可以用作分類,也可以用作回歸。
回歸
線性回歸
線性回歸是最經(jīng)典的回歸算法。
在統(tǒng)計(jì)學(xué)中,線性回歸(Linear regression)是利用稱為線性回歸方程的最小二乘函數(shù)對(duì)一個(gè)或多個(gè)自變量和因變量之間關(guān)系進(jìn)行建模的一種回歸分析。
這種函數(shù)是一個(gè)或多個(gè)稱為回歸系數(shù)的模型參數(shù)的線性組合。 只有一個(gè)自變量的情況稱為簡(jiǎn)單回歸,大于一個(gè)自變量情況的叫做多元回歸。
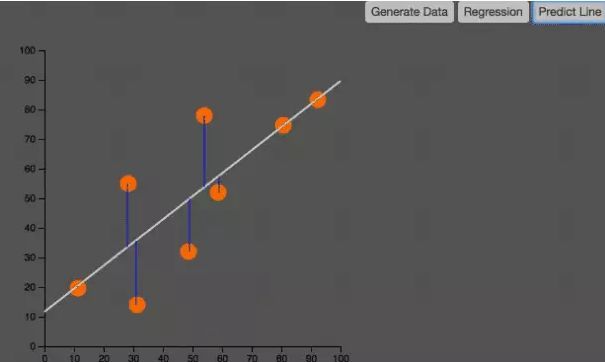
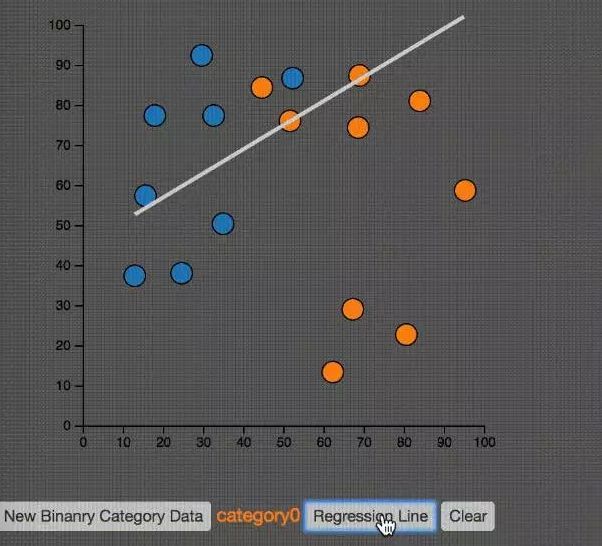
如上圖所示,線性回歸就是要找到一條直線,使得所有的點(diǎn)預(yù)測(cè)的失誤最小。也就是圖中的藍(lán)色直線段的和最小。這個(gè)圖很像我們第一個(gè)例子中的PCA。仔細(xì)觀察,分辨它們的區(qū)別。
如果對(duì)于算法的的準(zhǔn)確性要求比較高,推薦的回歸算法包括:隨機(jī)森林,神經(jīng)網(wǎng)絡(luò)或者Gradient Boosting Tree。
如果要求速度優(yōu)先,建議考慮決策樹和線性回歸。
分類
支持向量機(jī) SVM
如果對(duì)于分類的準(zhǔn)確性要求比較高,可使用的算法包括Kernel SVM,隨機(jī)森林,神經(jīng)網(wǎng)絡(luò)以及Gradient Boosting Tree。
給定一組訓(xùn)練實(shí)例,每個(gè)訓(xùn)練實(shí)例被標(biāo)記為屬于兩個(gè)類別中的一個(gè)或另一個(gè),SVM訓(xùn)練算法創(chuàng)建一個(gè)將新的實(shí)例分配給兩個(gè)類別之一的模型,使其成為非概率二元線性分類器。
SVM模型是將實(shí)例表示為空間中的點(diǎn),這樣映射就使得單獨(dú)類別的實(shí)例被盡可能寬的明顯的間隔分開。然后,將新的實(shí)例映射到同一空間,并基于它們落在間隔的哪一側(cè)來(lái)預(yù)測(cè)所屬類別。
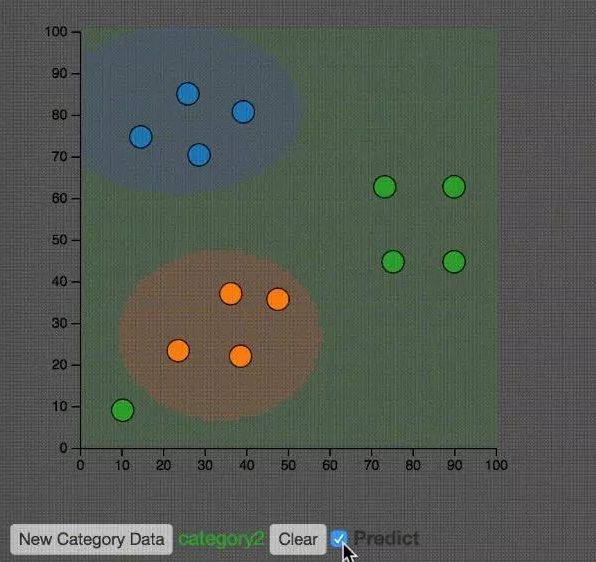
如上圖所示,SVM算法就是在空間中找到一條直線,能夠最好的分割兩組數(shù)據(jù)。使得這兩組數(shù)據(jù)到直線的距離的絕對(duì)值的和盡可能的大。
上圖示意了不同的核方法的不同分類效果。
決策樹
如果要求分類結(jié)果是可以解釋的,可以考慮決策樹或者邏輯回歸。
決策樹(decision tree)是一個(gè)樹結(jié)構(gòu)(可以是二叉樹或非二叉樹)。
其每個(gè)非葉節(jié)點(diǎn)表示一個(gè)特征屬性上的測(cè)試,每個(gè)分支代表這個(gè)特征屬性在某個(gè)值域上的輸出,而每個(gè)葉節(jié)點(diǎn)存放一個(gè)類別。
使用決策樹進(jìn)行決策的過(guò)程就是從根節(jié)點(diǎn)開始,測(cè)試待分類項(xiàng)中相應(yīng)的特征屬性,并按照其值選擇輸出分支,直到到達(dá)葉子節(jié)點(diǎn),將葉子節(jié)點(diǎn)存放的類別作為決策結(jié)果。
決策樹可以用于回歸或者分類,下圖是一個(gè)分類的例子。
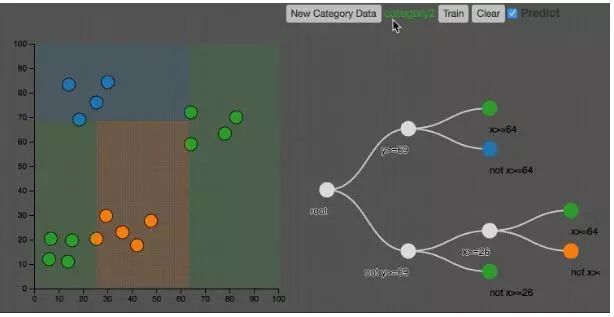
如上圖所示,決策樹把空間分割成不同的區(qū)域。
邏輯回歸
邏輯回歸雖然名字是回歸,但是卻是個(gè)分類算法。因?yàn)樗蚐VM類似是一個(gè)二分類,數(shù)學(xué)模型是預(yù)測(cè)1或者0的概率。所以我說(shuō)回歸和分類其實(shí)本質(zhì)上是一致的。
這里要注意邏輯回歸和線性SVM分類的區(qū)別
樸素貝葉斯
當(dāng)數(shù)據(jù)量相當(dāng)大的時(shí)候,樸素貝葉斯方法是一個(gè)很好的選擇。
15年我在公司給小伙伴們分享過(guò)bayers方法,可惜speaker deck被墻了,如果有興趣可以自行想辦法。
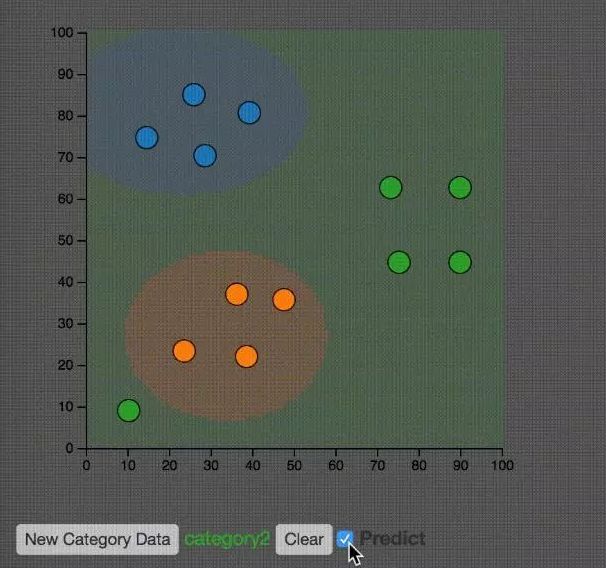
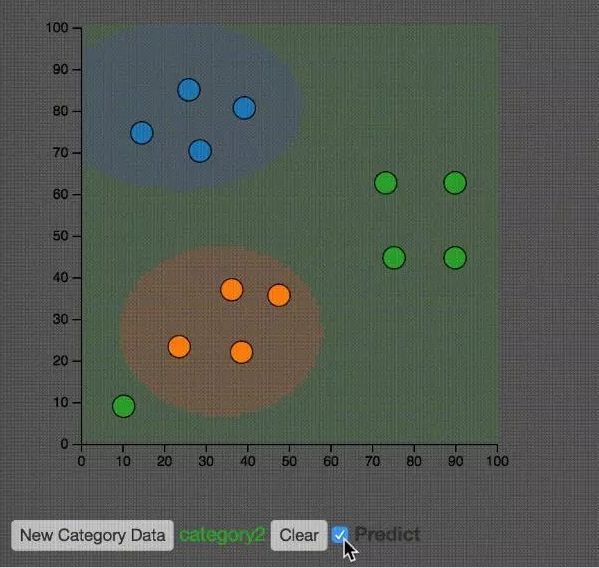
如上圖所示,大家可以思考一下左下的綠點(diǎn)對(duì)整體分類結(jié)果的影響。
KNN
KNN分類可能是所有機(jī)器學(xué)習(xí)算法里最簡(jiǎn)單的一個(gè)了。
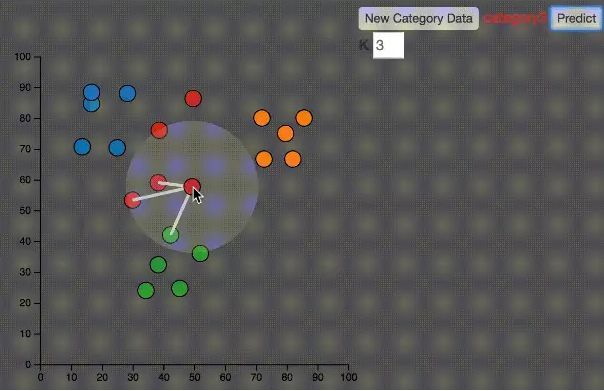
如上圖所示,K=3,鼠標(biāo)移動(dòng)到任何一個(gè)點(diǎn),就找到距離該點(diǎn)最近的K個(gè)點(diǎn),然后,這K個(gè)點(diǎn)投票,多數(shù)表決獲勝。就是這么簡(jiǎn)單。
總 結(jié)
本文利用二維交互圖幫助大家理解機(jī)器學(xué)習(xí)的基本算法,希望能增加大家對(duì)機(jī)器學(xué)習(xí)的各種方法有所了解。
本文來(lái)源:naughty
https://my.oschina.net/taogang/blog/1544709
免責(zé)聲明
數(shù)邦客-大數(shù)據(jù)價(jià)值構(gòu)建師(www.databanker.cn)除非特別注明,本站所載內(nèi)容來(lái)源于互聯(lián)網(wǎng)、微信公眾號(hào)等公開渠道,不代表本站觀點(diǎn),僅供參考、交流之目的。轉(zhuǎn)載的稿件版權(quán)歸原作者或機(jī)構(gòu)所有,如有侵權(quán),請(qǐng)聯(lián)系刪除。
產(chǎn)品簡(jiǎn)介
機(jī)器學(xué)習(xí)算法框架實(shí)戰(zhàn):Java和Python實(shí)現(xiàn)相關(guān)推薦
- 相關(guān)百科
- 相關(guān)知識(shí)
- 相關(guān)專欄
- 機(jī)器拋光設(shè)備
- 機(jī)器損壞險(xiǎn)
- 機(jī)器編碼
- 機(jī)器視覺
- 機(jī)外照明
- 機(jī)床主軸溫度
- 機(jī)床夾具零件及部件偏心輪用墊板
- 機(jī)床夾具零件及部件單面偏心輪
- 機(jī)床夾具零件及部件雙面偏心輪
- 機(jī)床夾具零件及部件定位插銷
- 機(jī)床夾具零件及部件活動(dòng)V 形塊
- 機(jī)床夾具零件及部件連接螺母
- 機(jī)床工具
- 機(jī)床拖鏈
- 機(jī)床數(shù)控化改造技術(shù)(第2版)
- 機(jī)床數(shù)控技術(shù)
- 在全縣非煤礦山和危化企業(yè)安全生產(chǎn)工作會(huì)議上的講話
- 支持并行工程和智能CAPP的制造資源建模技術(shù)
- 支持群體設(shè)計(jì)的工程數(shù)據(jù)庫(kù)管理系統(tǒng)的結(jié)構(gòu)及實(shí)現(xiàn)
- 云計(jì)算對(duì)企業(yè)信息化系統(tǒng)建設(shè)和運(yùn)營(yíng)的影響分析和改進(jìn)
- 政府和社會(huì)資本合作(PPP)項(xiàng)目物有所值評(píng)價(jià)
- 新的基于NGA/PCA和SVM的特征提取方法
- 在8度地震區(qū)建造低層純鋼框架結(jié)構(gòu)住宅的可行性分析
- 中華人民共和國(guó)國(guó)家標(biāo)準(zhǔn)建設(shè)工程工程量清單計(jì)價(jià)規(guī)范
- 永春縣農(nóng)田水利設(shè)施產(chǎn)權(quán)制度改革和運(yùn)行管護(hù)機(jī)制試點(diǎn)
- 異形人工挖孔樁和預(yù)應(yīng)力土層錨桿組合在基坑中的應(yīng)用
- 智能小區(qū)以太接入交換機(jī)SNMP代理設(shè)計(jì)與實(shí)現(xiàn)
- 政府投資建設(shè)項(xiàng)目在財(cái)務(wù)管理上面臨的風(fēng)險(xiǎn)和應(yīng)對(duì)措施
- 指路標(biāo)志(里程碑和百米碑)施工記錄表
- 在城鄉(xiāng)統(tǒng)籌就業(yè)和勞動(dòng)社會(huì)保障試點(diǎn)工作會(huì)議上的講話
- 高度集成化導(dǎo)航接收機(jī)系統(tǒng)射頻電路的設(shè)計(jì)與實(shí)現(xiàn)
- 基于CMOS工藝的二維風(fēng)速傳感器的設(shè)計(jì)和測(cè)試
最新詞條
安徽省政采項(xiàng)目管理咨詢有限公司
數(shù)字景楓科技發(fā)展(南京)有限公司
懷化市人民政府電子政務(wù)管理辦公室
河北省高速公路京德臨時(shí)籌建處
中石化華東石油工程有限公司工程技術(shù)分公司
手持無(wú)線POS機(jī)
廣東合正采購(gòu)招標(biāo)有限公司
上海城建信息科技有限公司
甘肅鑫禾國(guó)際招標(biāo)有限公司
燒結(jié)金屬材料
齒輪計(jì)量泵
廣州采陽(yáng)招標(biāo)代理有限公司河源分公司
高鋁碳化硅磚
博洛尼智能科技(青島)有限公司
燒結(jié)剛玉磚
深圳市東海國(guó)際招標(biāo)有限公司
搭建香蕉育苗大棚
SF計(jì)量單位
福建省中億通招標(biāo)咨詢有限公司
泛海三江
威海鼠尾草
Excel 數(shù)據(jù)處理與分析應(yīng)用大全
廣東國(guó)咨招標(biāo)有限公司
甘肅中泰博瑞工程項(xiàng)目管理咨詢有限公司
山東創(chuàng)盈項(xiàng)目管理有限公司
當(dāng)代建筑大師
拆邊機(jī)
廣西北纜電纜有限公司
大山檳榔
上海地鐵維護(hù)保障有限公司通號(hào)分公司
舌花雛菊
甘肅中維國(guó)際招標(biāo)有限公司
華潤(rùn)燃?xì)猓ㄉ虾#┯邢薰?
湖北鑫宇陽(yáng)光工程咨詢有限公司
GB8163標(biāo)準(zhǔn)無(wú)縫鋼管
中國(guó)石油煉化工程建設(shè)項(xiàng)目部
韶關(guān)市優(yōu)采招標(biāo)代理有限公司
莎草目
建設(shè)部關(guān)于開展城市規(guī)劃動(dòng)態(tài)監(jiān)測(cè)工作的通知
電梯平層準(zhǔn)確度
廣州利好來(lái)電氣有限公司
四川中澤盛世招標(biāo)代理有限公司